【2026年最新版】Julia言語完全入門ガイド:初心者のための徹底解説
目次
- Julia言語とは何か
- 他言語との比較
- インストール方法
- 基本文法
- 制御構文
- 配列とコレクション
- 関数とパッケージ管理
- まとめ
Julia言語とは何か:科学技術計算の新時代
Julia(ジュリア)は、2012年にMIT(マサチューセッツ工科大学)で公開された高性能プログラミング言語です。データサイエンス、機械学習、数値解析の分野で急速に普及しています。
Juliaが解決する「二言語問題」
従来の科学技術計算では深刻な課題がありました。研究者は試作段階でPythonやMATLABを使い、実際の計算では速度が必要なためCやFortranで書き直すという二重作業を強いられていました。
Juliaはこの問題を解決するため、「Pythonのような使いやすさ」と「Cのような実行速度」を両立する言語として開発されました。一つの言語で開発から本番運用まで完結できるのが最大の利点です。
Juliaの3つの最大の特徴
1. 圧倒的な高速性
JIT(Just-In-Time)コンパイル技術により、インタープリタ言語のように対話的に使えながら、実行時にはコンパイルされた機械語として動作します。多くの計算処理でC言語に匹敵し、Pythonより10〜100倍高速です。数値計算やループ処理では特に顕著な速度向上が見られます。
2. 数学的に自然な記法
数式をそのままコードに落とし込める直感的な構文を採用。Unicode文字を変数名に使えるため、数学記号(α、β、π、∑など)をそのままコード内で使用できます。物理学の方程式をそのままコードとして書けるため、論文とプログラムの対応が明確になります。
3. 豊富なエコシステム
データ可視化、機械学習、微分方程式、最適化など科学技術計算に必要なパッケージが充実。Python、R、C、Fortranなどの既存コードも簡単に呼び出せるため、既存の資産を活用しながら段階的に移行できます。
他言語との比較:Juliaの位置づけ
Python vs Julia:速度と構文の違い
実行速度の圧倒的な差
同じループ処理でも、Juliaは50〜100倍高速です。これは重要な違いで、データ量が多い場合に劇的な差が出ます:
# Python版:1000万回のループ
total = 0
for i in range(10000000):
total += i
# 実行時間: 約0.5-1秒
上記のPythonコードは、0から999万9999までの整数を順に加算しています。rangeは0から始まり、指定した数値(この場合10000000)の手前まで繰り返します。Pythonはインタープリタ言語なので、このような単純なループでも比較的時間がかかります。
# Julia版:同じ処理
total = 0
for i in 1:10000000
total += i
end
# 実行時間: 約0.01-0.02秒
Juliaでは同じ処理が圧倒的に高速です。1:10000000は「1から1000万まで」を意味する範囲オブジェクトです。Juliaは実行時にコンパイルされるため、このような単純なループでもC言語並みの速度が出ます。変数totalに各数値を加算し続け、最終的に1から1000万までの総和が格納されます。
配列インデックスの重要な違い
これは初心者が最も戸惑う違いの一つです。配列の最初の要素にアクセスする際の番号が異なります:
- Python: 0から始まり、範囲の終端を含まない
- Julia: 1から始まり、範囲の終端を含む
# Python:インデックスは0から
arr = [10, 20, 30]
arr[0] # 10(最初の要素)
arr[1:3] # [20, 30](インデックス1と2、3は含まない)
Pythonでは配列の最初の要素はインデックス0でアクセスします。arr[0]は10を返します。スライス(範囲指定)では、arr[1:3]と書くとインデックス1と2の要素(つまり20と30)が取得されますが、3は含まれません。この「終端を含まない」仕様に注意が必要です。
# Julia:インデックスは1から
arr = [10, 20, 30]
arr[1] # 10(最初の要素)
arr[2:3] # [20, 30](インデックス2と3、3を含む)
Juliaでは配列の最初の要素はインデックス1でアクセスします。これは数学的な慣習(ベクトルの第1成分、第2成分...)に従っています。arr[1]は10を返します。範囲指定では、arr[2:3]と書くとインデックス2と3の両方の要素(20と30)が取得され、終端も含まれます。Pythonから移行する際は、この違いに特に注意してください。
MATLAB vs Julia:コスト面の優位性
構文はMATLABと非常に似ていますが、Juliaは完全に無料のオープンソースです:
% MATLAB:行列の定義と演算
A = [1 2 3; 4 5 6];
B = A * 2;
MATLABでは、セミコロン(;)で行を区切って2×3の行列Aを定義しています。1行目は[1, 2, 3]、2行目は[4, 5, 6]です。A * 2は行列Aの全要素を2倍にしています。MATLABは非常に強力ですが、基本ライセンスだけで年間数万円から数十万円かかります。
# Julia:同じ処理が無料で可能
A = [1 2 3; 4 5 6]
B = A * 2
Juliaでも全く同じ構文で行列を定義できます。スペースで列を区切り、セミコロンで行を区切ります。A * 2も同様に全要素を2倍にします。構文がほぼ同一なので、MATLABユーザーは違和感なく移行できます。しかもJuliaは完全に無料で、何台のコンピュータにインストールしても追加費用は一切かかりません。
C/C++ vs Julia:開発効率の圧倒的な差
C言語と同等の速度を持ちながら、コンパイル不要で即座に実行できます:
// C言語:型宣言必須、コンパイル必要
#include <stdio.h>
int main() {
int total = 0;
for (int i = 0; i < 10000000; i++) {
total += i;
}
printf("%d\n", total);
return 0;
}
// 実行手順:
// 1. gcc program.c -o program でコンパイル
// 2. ./program で実行
C言語では、まずヘッダーファイル(stdio.h)をインクルードし、main関数を定義する必要があります。変数totalとiは明示的にint型として宣言しなければなりません。forループで0から999万9999まで加算し、printfで結果を表示します。しかし、実行前に必ずgccコマンドでコンパイルする必要があり、エラーがあれば修正してまたコンパイルという手順を繰り返します。開発サイクルが長くなるのが欠点です。
# Julia:型宣言不要、即座に実行可能
total = 0
for i in 1:10000000
total += i
end
println(total)
# 実行:julia program.jl と打つだけ
Juliaでは型宣言は任意(書いても書かなくてもよい)で、コンパイル手順も不要です。julia program.jlと打てば即座に実行されます。コードを修正したら、また同じコマンドで即実行できます。開発効率が圧倒的に高く、それでいてC言語並みの速度が出るのがJuliaの強みです。totalやiの型は自動的に推論され、最適化されたコードが生成されます。
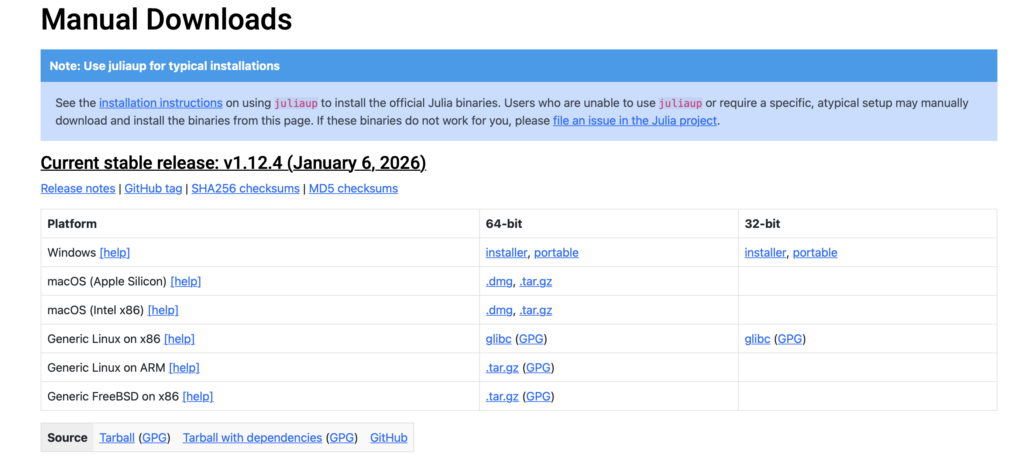
インストール方法
Windows環境
- Webブラウザでjulialang.orgにアクセス
- トップページの「Download」ボタンをクリック
- 「Windows (64-bit)」を選択してダウンロード
- ダウンロードした「julia-x.x.x-win64.exe」をダブルクリック
- インストールウィザードで**「Add Julia to PATH」に必ずチェック**を入れる
- これにより、どのフォルダからでも「julia」コマンドが使えるようになります
- 「Install」をクリックして完了を待つ
インストール後、コマンドプロンプト(Windowsキー + R → 「cmd」と入力)を開き、juliaと入力してEnterを押せば起動します。
macOS環境
方法1: 公式インストーラー
- julialang.orgにアクセス
- 「Download」から自分のMacに合ったバージョンを選択
- Intel Macなら「macOS (x86-64)」
- M1/M2/M3 Macなら「macOS (Apple Silicon)」
- ダウンロードしたdmgファイルを開く
- Julia.appをApplicationsフォルダにドラッグ&ドロップ
- ターミナルで使えるようにシンボリックリンクを作成:
sudo ln -s /Applications/Julia-1.10.app/Contents/Resources/julia/bin/julia /usr/local/bin/julia
このコマンドは、Juliaの実行ファイルへのショートカットを/usr/local/binに作成します。これにより、ターミナルでどこからでも「julia」と打つだけで起動できるようになります。
方法2: Homebrew(推奨)
Homebrewがインストールされている場合、これが最も簡単です:
brew install julia
このコマンド一つで、ダウンロードからインストール、パスの設定まで全て自動で行われます。
Linux環境 (Ubuntu/Debian)
公式バイナリ使用(最新版が使えるため推奨)
# 最新版のバイナリをダウンロード
wget https://julialang-s3.julialang.org/bin/linux/x64/1.10/julia-1.10.0-linux-x86_64.tar.gz
# ダウンロードしたファイルを解凍
tar -xvzf julia-1.10.0-linux-x86_64.tar.gz
# 解凍したフォルダを/optに移動(システム全体で使えるようにする)
sudo mv julia-1.10.0 /opt/
# シンボリックリンクを作成(どこからでも「julia」コマンドで起動できるようにする)
sudo ln -s /opt/julia-1.10.0/bin/julia /usr/local/bin/julia
各コマンドの意味を解説します。wgetはファイルをダウンロードするコマンド、tarは圧縮ファイルを解凍するコマンドです。mvは移動コマンドで、解凍したJuliaを/optディレクトリに移動しています。最後のlnコマンドでシンボリックリンク(ショートカット)を作成し、どのディレクトリからでも「julia」と打てば起動できるようにしています。
インストールの確認
正しくインストールされたか確認しましょう:
julia> println("Hello, Julia!")
Hello, Julia!
julia> 2 + 2
4
julia> versioninfo()
Julia Version 1.10.0
...
最初のprintlnは文字列を表示する関数です。"Hello, Julia!"という文字列が表示されれば成功です。2 + 2は単純な計算で、4が返ればJuliaが正常に動作しています。versioninfo()はJuliaのバージョン情報を表示するコマンドで、インストールされたバージョンやシステム情報が確認できます。
基本文法:はじめの一歩
REPLの4つのモード
JuliaのREPL(Read-Eval-Print Loop、対話型環境)には複数のモードがあり、特定のキーを押すことで切り替えられます。これにより効率的に作業できます:
Juliaモード(デフォルト)
通常のプログラミングモードです。起動直後はこのモードになっています:
julia> 2 + 3
5
julia> println("Hello!")
Hello!
プロンプトが「julia>」になっているのがJuliaモードです。ここで通常のJuliaコードを実行します。2 + 3は5を返し、println関数は文字列を表示します。
パッケージモード(]キー)
閉じ括弧「]」キーを押すと、プロンプトが「pkg>」に変わります。ここでパッケージの追加や削除、確認ができます:
julia> ] # ]キーを押すとモード切替
(@v1.10) pkg> add Plots
(@v1.10) pkg> status
add Plotsは「Plots」という可視化パッケージをインストールするコマンドです。statusは現在インストールされているパッケージの一覧を表示します。Backspaceキーを押せば元のJuliaモードに戻ります。
ヘルプモード(?キー)
疑問符「?」キーを押すと、プロンプトが「help?>」に変わります。関数やキーワードの説明を見られます:
julia> ? # ?キーを押すとヘルプモードへ
help?> println
println([io::IO], xs...)
Print (using print) xs to io followed by a newline.
関数名を入力するとその使い方や説明が表示されます。printlnと入力すれば、println関数の詳しい説明が英語で表示されます。プログラミング中に関数の使い方がわからなくなったら、このモードで即座に確認できます。
シェルモード(;キー)
セミコロン「;」キーを押すと、プロンプトが「shell>」に変わります。ここでOSのコマンド(LinuxのlsやWindowsのdirなど)を実行できます:
julia> ; # ;キーを押すとシェルモードへ
shell> ls # Linuxのlsコマンドでファイル一覧表示
shell> dir # Windowsのdirコマンドでファイル一覧表示
Juliaを終了せずに、ファイルの確認やディレクトリの移動などができて便利です。Backspaceで元のモードに戻ります。
変数と基本データ型
Juliaでは変数を宣言する際、型を指定する必要はありません。自動的に適切な型が推論されます:
# 整数(Int64型に自動推論される)
x = 10
println(typeof(x)) # Int64
# 浮動小数点数(Float64型に自動推論)
y = 3.14
println(typeof(y)) # Float64
# 文字列(ダブルクォートで囲む)
name = "Julia"
println(typeof(name)) # String
# 文字(シングルクォートで囲む)
initial = 'J'
println(typeof(initial)) # Char
# 論理値(true または false)
is_fast = true
println(typeof(is_fast)) # Bool
typeof関数は変数の型を確認する関数です。x = 10と書くだけで、Juliaは自動的にxを64ビット整数(Int64)として扱います。小数点を含むy = 3.14は64ビット浮動小数点数(Float64)になります。
文字列と文字の違いに注意してください。"Julia"はダブルクォートで囲むので文字列(String型)、'J'はシングルクォートで囲むので文字(Char型)です。文字列は複数の文字の集まり、文字は1文字だけを表します。
論理値(Bool型)はtrueまたはfalseの2つの値しか持ちません。条件判定などで使用します。
Unicode文字の活用:Juliaの強力な機能
Juliaでは数学記号を変数名として使用できます。これが他の言語にはない大きな特徴です:
# ギリシャ文字を変数名に使用
α = 0.5
β = 2.0
γ = α + β # 2.5
# 数学記号も使用可能
∑ = sum([1, 2, 3, 4, 5]) # 15(合計)
π_value = π # 3.141592653589793(円周率)
# 入力方法(LaTeX形式):
# \alpha + Tab → α
# \beta + Tab → β
# \sum + Tab → ∑
# \pi + Tab → π
これらの記号を入力するには、バックスラッシュ(\)に続けてLaTeX形式の名前を入力し、Tabキーを押します。例えば、\alphaと入力してTabを押すとαに変換されます。
この機能により、物理学や数学の論文に出てくる式をそのままコードに落とし込めます。例えば、論文に「速度v = αt + β」と書いてあれば、コードもv = α*t + βと書けるので、対応が明確になります。
sum関数は配列の要素を合計する関数です。sum([1, 2, 3, 4, 5])は1+2+3+4+5=15を計算します。πは円周率で、最初から定義されている定数です。
数値計算の基本
Juliaは数値計算に最適化されており、基本的な演算は直感的に記述できます:
# 四則演算
a = 10 + 5 # 15(加算)
b = 10 - 5 # 5(減算)
c = 10 * 5 # 50(乗算)
d = 10 / 5 # 2.0(除算、結果は常に浮動小数点数)
# べき乗
e = 2^10 # 1024(2の10乗)
# 整数除算と剰余
f = 17 ÷ 5 # 3(整数除算、小数点以下切り捨て)
g = 17 % 5 # 2(剰余、17を5で割った余り)
# 数学関数(追加ライブラリ不要で使える)
result = sin(π/2) + cos(0) # 2.0
重要なポイント:
- 除算(/)は常に浮動小数点数を返す:10 / 5の結果は整数の2ではなく、浮動小数点数の2.0になります。これは整数同士の除算でも同じです。整数の結果が欲しい場合は整数除算(÷)を使います。
- 整数除算(÷)の使い方:17 ÷ 5は3を返します(17を5で割って小数点以下を切り捨て)。÷記号は\divと入力してTabキーを押すと入力できます。
- 剰余演算子(%):17 % 5は2を返します。これは17を5で割った余りです(17 = 5×3 + 2なので、余りは2)。
- 数学関数が標準装備:sin(サイン)、cos(コサイン)、sqrt(平方根)などの数学関数が最初から使えます。Pythonのようにmathモジュールをインポートする必要はありません。sin(π/2)はπ/2(90度)のサイン値で1.0、cos(0)は0度のコサイン値で1.0なので、合計は2.0になります。
文字列操作の基本
文字列の扱い方を学びましょう。Juliaの文字列操作は直感的で強力です:
# 文字列の結合(*演算子を使用)
greeting = "Hello, " * "Julia!"
println(greeting) # "Hello, Julia!"
文字列の結合には「」演算子を使います(「+」ではありません)。これは数学的に、文字列の結合は加法ではなく乗法的な操作だからです。"Hello, "と"Julia!"をでつなぐと"Hello, Julia!"になります。
文字列補間(変数の埋め込み)
変数の値を文字列に埋め込む強力な機能です:
# $記号で変数を埋め込む
name = "World"
message = "Hello, $name!"
println(message) # "Hello, World!"
$記号の後に変数名を書くと、その変数の値が自動的に文字列に埋め込まれます。nameには"World"が入っているので、$nameは"World"に置き換えられ、最終的に"Hello, World!"という文字列になります。
複雑な式の埋め込み
# $()で囲むと計算式も埋め込める
x = 10
y = 20
result = "$(x) + $(y) = $(x + y)"
println(result) # "10 + 20 = 30"
$()の形式を使うと、括弧内の式を評価した結果を埋め込めます。$(x)はxの値(10)、$(y)はyの値(20)、$(x + y)は計算結果(30)がそれぞれ文字列に埋め込まれます。
文字列の操作関数
text = " Hello, Julia! "
# 前後の空白を除去
trimmed = strip(text) # "Hello, Julia!"
# 大文字・小文字変換
upper = uppercase(text) # " HELLO, JULIA! "
lower = lowercase(text) # " hello, julia! "
# 文字列の置換(置き換え)
replaced = replace(text, "Julia" => "World") # " Hello, World! "
strip関数は文字列の前後にある空白(スペースやタブ)を削除します。uppercase関数は全ての文字を大文字に、lowercase関数は全て小文字に変換します。replace関数は、第2引数の"Julia"を見つけて"World"に置き換えます。"元の文字列" => "新しい文字列"の形式で指定します。
制御構文:プログラムの流れを制御
if文による条件分岐
プログラムの流れを条件によって変える基本的な構文です:
x = 10
if x > 0
println("正の数です")
elseif x < 0
println("負の数です")
else
println("ゼロです")
end
このコードでは、まずxが0より大きいかチェックします。xは10なので条件を満たし、「正の数です」が表示されます。もしxが負の数なら2番目の条件(elseif x < 0)が評価され、どちらでもなければelse節(つまりx = 0の場合)が実行されます。
重要:Juliaでは「elseif」は一語です(else ifではありません)。そして必ず「end」キーワードでif文を終了します。Pythonのようにインデントだけで判断せず、Javaのように波括弧{}も使いません。明示的に「end」と書くことで、ブロックの終わりがはっきりします。
複数条件の組み合わせ
score = 85
attendance = 90
# AND条件(&&):両方の条件を満たす必要がある
if score >= 80 && attendance >= 80
println("合格です")
end
# 出力:"合格です"
# OR条件(||):どちらか一方を満たせばよい
if score >= 90 || attendance >= 95
println("優秀です")
else
println("良好です")
end
# 出力:"良好です"
&&(AND演算子)は両方の条件が真の時だけ真になります。この例では、scoreが80以上かつattendanceも80以上なので、両方満たして「合格です」が表示されます。
||(OR演算子)はどちらか一方でも真なら真になります。scoreは90未満、attendanceも95未満なので、どちらの条件も満たさず、else節の「良好です」が表示されます。
三項演算子による簡潔な記述
短い条件分岐には三項演算子が便利です:
age = 25
status = age >= 20 ? "成人" : "未成年"
println(status) # "成人"
三項演算子の形式は「条件 ? 真の場合の値 : 偽の場合の値」です。ageは25なので、age >= 20は真(true)となり、"成人"が返されてstatusに代入されます。もしageが18なら"未成年"が返されます。if-else文を1行で書けるので、簡単な条件分岐に便利です。
for文によるループ(繰り返し処理)
同じ処理を何度も繰り返すための構文です。プログラミングで最も頻繁に使われる機能の一つです:
# 1から10まで繰り返す
for i in 1:10
println(i)
end
# 出力:1, 2, 3, 4, 5, 6, 7, 8, 9, 10
1:10は「1から10まで」を表す範囲オブジェクトです。for文はこの範囲の各値を順にiに代入して処理を実行します。最初のループでiは1、2回目は2...と続き、10回目でiは10になります。println(i)により、各ループで現在のiの値が表示されます。
配列の要素を順に処理
fruits = ["apple", "banana", "orange"]
for fruit in fruits
println("I like ", fruit)
end
# 出力:
# I like apple
# I like banana
# I like orange
fruitsは3つの文字列を含む配列です。for文は配列の各要素を順にfruitという変数に代入します。1回目のループではfruitは"apple"、2回目は"banana"、3回目は"orange"になります。println("I like ", fruit)は2つの引数(文字列とfruit)を連結して表示します。
インデックス番号と値を同時に取得
fruits = ["apple", "banana", "orange"]
for (index, fruit) in enumerate(fruits)
println("$index: $fruit")
end
# 出力:
# 1: apple
# 2: banana
# 3: orange
enumerate関数は配列の各要素に対して(インデックス番号、値)のペアを返します。Juliaのインデックスは1から始まるので、appleのインデックスは1、bananaは2、orangeは3です。(index, fruit)のように括弧で囲むことで、ペアを2つの変数に分解して受け取れます。これを「分割代入」といいます。
ステップを指定したループ
# 1から10まで2ずつ増加(奇数のみ)
for i in 1:2:10
println(i)
end
# 出力:1, 3, 5, 7, 9
# 10から1まで逆順
for i in 10:-1:1
println(i)
end
# 出力:10, 9, 8, 7, 6, 5, 4, 3, 2, 1
範囲の形式は「開始:ステップ:終了」です。1:2:10は「1から10まで2ずつ増やす」という意味で、1, 3, 5, 7, 9の5回ループします。10は含まれません(9の次は11になってしまうため)。
10:-1:1は「10から1まで1ずつ減らす」という意味です。負のステップ値を使うことで逆順のループができます。カウントダウンなどに使えます。
while文とbreak、continue
条件が真である限り処理を繰り返す構文です。繰り返し回数が事前にわからない場合に便利です:
count = 0
while count < 5
println("Count: $count")
count += 1
end
# 出力:
# Count: 0
# Count: 1
# Count: 2
# Count: 3
# Count: 4
while文は「count < 5」という条件が真(true)の間、処理を繰り返します。最初はcount = 0なので条件を満たし、ループ内の処理が実行されます。println("Count: $count")で現在のcountの値を表示し、count += 1でcountに1を加えます(count = count + 1の省略形)。countが5になると条件が偽(false)になり、ループが終了します。
break文でループを途中で抜ける
for i in 1:100
if i > 10
break # ループを即座に終了
end
println(i)
end
# 出力:1から10まで(11以降は表示されない)
本来なら1から100まで繰り返すループですが、break文により途中で終了します。各ループでまずiが10より大きいかチェックします。iが11になった時点でif条件が真になり、breakが実行されてループが終了します。残りの89回の繰り返しはスキップされ、効率的です。
continue文で次の繰り返しへスキップ
for i in 1:10
if i % 2 == 0 # iが偶数なら
continue # 以降の処理をスキップ
end
println(i) # 奇数のみ表示される
end
# 出力:1, 3, 5, 7, 9(偶数は表示されない)
i % 2は「iを2で割った余り」を計算します。偶数なら余りは0、奇数なら1です。i % 2 == 0は「余りが0」つまり「iが偶数」を意味します。偶数の場合、continue文が実行され、そのループの残りの処理(println(i))がスキップされて、次のiに進みます。結果として奇数だけが表示されます。
breakとcontinueの違い:breakはループ全体を終了しますが、continueは現在の繰り返しだけをスキップして次の繰り返しに進みます。
配列とコレクション
配列の作成と基本操作
配列は複数のデータをまとめて扱うための基本的なデータ構造です:
# 1次元配列(ベクトル)の作成
arr1 = [1, 2, 3, 4, 5]
println(arr1) # [1, 2, 3, 4, 5]
角括弧[]で要素を囲み、カンマで区切って配列を作ります。この配列arr1には5つの整数が順番に格納されています。配列の各要素には番号(インデックス)が付けられ、後から個別にアクセスできます。
型を指定した配列の作成
# Float64型(64ビット浮動小数点数)として配列を作成
arr2 = Float64[1, 2, 3, 4, 5]
println(arr2) # [1.0, 2.0, 3.0, 4.0, 5.0]
println(typeof(arr2)) # Vector{Float64}
型名[...]の形式で、特定の型の配列を作成できます。整数1, 2, 3...を渡していますが、Float64[]と指定しているため、全て浮動小数点数1.0, 2.0, 3.0...に変換されて格納されます。typeof関数で確認すると、Vector{Float64}(Float64型の要素を持つベクトル)と表示されます。
範囲から配列を生成
# 範囲オブジェクトを配列に変換
arr3 = collect(1:10)
println(arr3) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# ステップを指定して配列を作成
arr4 = collect(1:2:10)
println(arr4) # [1, 3, 5, 7, 9]
1:10は範囲オブジェクトで、メモリ効率のため実際の配列は作られていません。collect関数を使うことで、範囲オブジェクトを実際の配列に変換します。1:2:10は「1から10まで2ずつ増やす」という意味なので、collect(1:2:10)は[1, 3, 5, 7, 9]という配列になります。
特定の値で配列を初期化
# 全ての要素が0の配列を作成
zeros_arr = zeros(5)
println(zeros_arr) # [0.0, 0.0, 0.0, 0.0, 0.0]
# 全ての要素が1の配列を作成
ones_arr = ones(5)
println(ones_arr) # [1.0, 1.0, 1.0, 1.0, 1.0]
# 整数型で0の配列を作成
int_zeros = zeros(Int, 5)
println(int_zeros) # [0, 0, 0, 0, 0]
zeros関数は指定した個数の0で埋められた配列を作ります。zeros(5)は5個の0.0(Float64型)を持つ配列を作成します。ones関数も同様で、1.0で埋められた配列を作ります。デフォルトはFloat64型ですが、zeros(Int, 5)のように第1引数で型を指定すれば、整数型の配列を作れます。
配列の要素へのアクセス
arr = [10, 20, 30, 40, 50]
# インデックスで要素にアクセス(重要:1から始まる)
first_element = arr[1] # 10(最初の要素)
third_element = arr[3] # 30(3番目の要素)
last_element = arr[end] # 50(最後の要素)
println("最初: $first_element") # "最初: 10"
println("3番目: $third_element") # "3番目: 30"
println("最後: $last_element") # "最後: 50"
最重要ポイント:Juliaの配列インデックスは1から始まります(Pythonは0から)。arr[1]は最初の要素(10)、arr[3]は3番目の要素(30)を返します。endは特別なキーワードで、配列の最後のインデックスを表します。この例ではendは5なので、arr[end]はarr[5]と同じで50を返します。
範囲指定で複数の要素を取得
arr = [10, 20, 30, 40, 50]
# インデックス2から4までの要素を取得
subset = arr[2:4]
println(subset) # [20, 30, 40]
# 最初の3つの要素
first_three = arr[1:3]
println(first_three) # [10, 20, 30]
# 最後の2つの要素
last_two = arr[end-1:end]
println(last_two) # [40, 50]
arr[2:4]は「インデックス2から4まで」を意味し、[20, 30, 40]を返します。重要:Juliaでは終端も含まれます(Pythonでは含まれない)。end-1は「最後から2番目」を意味するので、arr[end-1:end]は最後の2要素を返します。
多次元配列とブロードキャスト演算
2次元配列(行列)の作成
# 2×3の行列を作成(2行3列)
matrix = [1 2 3; 4 5 6]
println(matrix)
# 出力:
# 2×3 Matrix{Int64}:
# 1 2 3
# 4 5 6
セミコロン(;)で行を区切ります。最初の行は[1 2 3]、2行目は[4 5 6]です。スペースで列を区切ります。この行列は2行3列の構造を持ち、6つの要素が格納されています。
ブロードキャスト演算:配列全体への演算適用
Juliaの強力な機能の一つで、ドット(.)演算子を使って配列の各要素に同じ操作を適用できます:
# 配列の各要素を2乗
arr = [1, 2, 3, 4, 5]
squared = arr .^ 2
println(squared) # [1, 4, 9, 16, 25]
# 各要素のsin値を計算
sine_vals = sin.(arr)
println(sine_vals) # [0.841..., 0.909..., 0.141..., -0.756..., -0.958...]
# 各要素の平方根を計算
sqrt_vals = sqrt.(arr)
println(sqrt_vals) # [1.0, 1.414..., 1.732..., 2.0, 2.236...]
.^演算子は「各要素に対してべき乗を適用」という意味です。arr .^ 2は、配列の各要素を2乗します(1²=1, 2²=4, 3²=9...)。普通の^だと配列全体の演算になってエラーが出ますが、.^なら要素ごとの演算になります。
sin.(arr)のように、関数名の後に.を付けると、配列の各要素に関数を適用します。sin.(arr)は[sin(1), sin(2), sin(3), sin(4), sin(5)]と同じ意味ですが、ループを書く必要がありません。
複数の配列に対するブロードキャスト
a = [1, 2, 3]
b = [4, 5, 6]
# 要素ごとの加算
c = a .+ b
println(c) # [5, 7, 9](1+4, 2+5, 3+6)
# 要素ごとの乗算
d = a .* b
println(d) # [4, 10, 18](1*4, 2*5, 3*6)
# より複雑な演算も可能
e = (a .^ 2) .+ (b .* 2)
println(e) # [9, 14, 21](1²+4*2, 2²+5*2, 3²+6*2)
a .+ bは、aとbの対応する要素を加算します。a[1] + b[1] = 5, a[2] + b[2] = 7, a[3] + b[3] = 9となり、[5, 7, 9]が返されます。
最後の例は複雑ですが、順を追えば理解できます。a .^ 2は[1, 4, 9]、b .* 2は[8, 10, 12]、これらを要素ごとに足すと[9, 14, 21]になります。ドット演算子を使うことで、複雑な数値計算もシンプルに書けます。
配列操作の便利な関数
arr = [3, 1, 4, 1, 5, 9, 2, 6]
# 配列の長さ(要素数)
len = length(arr)
println(len) # 8
# 末尾に要素を追加(!付き関数は元の配列を変更する)
push!(arr, 10)
println(arr) # [3, 1, 4, 1, 5, 9, 2, 6, 10]
# 末尾の要素を削除して返す
last_val = pop!(arr)
println(last_val) # 10
println(arr) # [3, 1, 4, 1, 5, 9, 2, 6](10が削除された)
# ソート(昇順):元の配列は変更しない
sorted_arr = sort(arr)
println(sorted_arr) # [1, 1, 2, 3, 4, 5, 6, 9]
println(arr) # [3, 1, 4, 1, 5, 9, 2, 6](変更されていない)
# ソート:元の配列を変更する(!付き)
sort!(arr)
println(arr) # [1, 1, 2, 3, 4, 5, 6, 9](変更された)
Juliaの慣習として、関数名の末尾に!(感嘆符)が付いている関数は、引数の配列を直接変更します。push!(arr, 10)はarrの末尾に10を追加し、arrそのものが変更されます。pop!(arr)は末尾の要素を削除して返します。
sort(arr)は元の配列を変更せず、ソートされた新しい配列を返します。一方、sort!(arr)は元の配列arrをソートして、arrそのものが変更されます。!の有無で動作が大きく異なるので注意が必要です。
統計関数の使用
using Statistics # 統計関数を使うためにインポート
arr = [3, 1, 4, 1, 5, 9, 2, 6]
# 合計
total = sum(arr)
println(total) # 31
# 平均値
avg = mean(arr)
println(avg) # 3.875
# 最大値と最小値
max_val = maximum(arr)
min_val = minimum(arr)
println("最大: $max_val, 最小: $min_val") # "最大: 9, 最小: 1"
sum関数は全要素の合計を返します(3+1+4+1+5+9+2+6=31)。mean関数は平均値を計算しますが、これを使うには最初にusing Statisticsと書いてStatisticsパッケージを読み込む必要があります。maximum関数は最大値(9)、minimum関数は最小値(1)を返します。
関数の定義と多重ディスパッチ
基本的な関数定義
関数は処理をまとめて再利用可能にする重要な機能です:
# 通常の関数定義
function add(x, y)
return x + y
end
result = add(3, 5)
println(result) # 8
functionキーワードで関数を定義し、関数名と引数を指定します。add(x, y)はxとyという2つの引数を受け取ります。return文で計算結果を返します。add(3, 5)を呼び出すと、x=3, y=5として関数内の処理が実行され、3+5=8が返されます。
短縮形の関数定義
# 1行で書ける短縮形
add(x, y) = x + y
println(add(10, 20)) # 30
単純な関数は、function...endを使わず1行で定義できます。add(x, y) = x + yは上記の長い形式と全く同じ動作をしますが、よりシンプルです。単純な計算や変換を行う関数に適しています。
複数の戻り値を返す
# 複数の値を同時に返す
function calculate(x, y)
return x + y, x - y, x * y
end
# 複数の変数で受け取る(分割代入)
sum_val, diff_val, prod_val = calculate(10, 5)
println("和: $sum_val") # "和: 15"
println("差: $diff_val") # "差: 5"
println("積: $prod_val") # "積: 50"
Juliaでは複数の値をカンマで区切って返せます。return x + y, x - y, x * yは3つの値(和、差、積)を返します。呼び出し側では、sum_val, diff_val, prod_val = calculate(10, 5)のように複数の変数で受け取れます。これを「分割代入」といいます。1回の関数呼び出しで複数の計算結果を得られるので効率的です。
多重ディスパッチ:Juliaの革新的機能
多重ディスパッチは、引数の型の組み合わせによって実行される関数が自動的に選択される仕組みです。これがJuliaの最も特徴的な機能です:
# 整数同士の処理
function process(x::Int, y::Int)
println("整数の計算: $(x + y)")
return x + y
end
# 浮動小数点数同士の処理
function process(x::Float64, y::Float64)
println("小数の計算: $(x + y)")
return x + y
end
# 文字列同士の処理
function process(x::String, y::String)
println("文字列の結合: $(x * y)")
return x * y
end
同じ「process」という名前の関数を、引数の型を変えて複数定義しています。::Intは「Int型(整数)」、::Float64は「Float64型(浮動小数点数)」、::Stringは「String型(文字列)」を意味します。
多重ディスパッチの自動選択
# 使用例
process(3, 5) # "整数の計算: 8"
process(3.14, 2.71) # "小数の計算: 5.85"
process("Hello", "World") # "文字列の結合: HelloWorld"
同じprocess関数を呼んでいますが、引数の型によって実行される関数が自動的に選ばれます:
- process(3, 5):両方とも整数なので、process(x::Int, y::Int)が実行される
- process(3.14, 2.71):両方とも浮動小数点数なので、process(x::Float64, y::Float64)が実行される
- process("Hello", "World"):両方とも文字列なので、process(x::String, y::String)が実行される
プログラマーがif文で型をチェックする必要はありません。Juliaが自動的に最適な関数を選びます。
多重ディスパッチの利点
- コードが読みやすい:各型の処理が別々の関数として定義されるため、構造が明確
- 高速:コンパイル時に型が確定するため、最適化されたコードが生成される
- 拡張性が高い:新しい型に対応する関数を後から追加できる
Pythonなら以下のように書く必要があります:
# Python版(if文で型チェックが必要)
def process(x, y):
if isinstance(x, int) and isinstance(y, int):
print(f"整数の計算: {x + y}")
return x + y
elif isinstance(x, float) and isinstance(y, float):
print(f"小数の計算: {x + y}")
return x + y
elif isinstance(x, str) and isinstance(y, str):
print(f"文字列の結合: {x + y}")
return x + y
Juliaの多重ディスパッチの方が、読みやすく、拡張しやすく、しかも高速です。
実用的な多重ディスパッチの例
# 数値に対する2乗
square(x::Number) = x * x
# 配列に対する2乗(要素ごと)
square(arr::Array) = arr .^ 2
# 文字列に対する2乗(2回繰り返し)
square(s::String) = s * s
# 使用例
println(square(5)) # 25(数値の2乗)
println(square([1, 2, 3])) # [1, 4, 9](配列の各要素を2乗)
println(square("Hi")) # "HiHi"(文字列を2回繰り返し)
同じ「square」という名前でも、引数の型によって全く異なる動作をします。5を渡せば数値計算、配列を渡せば要素ごとの計算、文字列を渡せば繰り返しが実行されます。直感的で拡張可能なコードが書けます。
パッケージ管理
パッケージのインストールと使用
Juliaには豊富なパッケージエコシステムがあり、様々な機能を簡単に追加できます:
# REPLでパッケージモードへ切替(]キーを押す)
julia> ]
# Plotsパッケージ(グラフ描画)をインストール
(@v1.10) pkg> add Plots
# DataFramesパッケージ(データフレーム操作)をインストール
(@v1.10) pkg> add DataFrames
# インストール済みパッケージの確認
(@v1.10) pkg> status
# Backspaceキーで通常モードへ戻る
]キーを押すとパッケージモードに入り、プロンプトが「pkg>」に変わります。add Plotsと入力すれば、Plotsパッケージが自動的にダウンロードされてインストールされます。statusコマンドで、現在インストールされているパッケージとそのバージョンを確認できます。
パッケージの使用例
# Plotsパッケージを読み込む
using Plots
# グラフを描画
x = [1, 2, 3, 4, 5]
y = [1, 4, 9, 16, 25] # y = x²
plot(x, y, label="y=x²", linewidth=2)
using Plotsと書くことで、Plotsパッケージの機能が使えるようになります。plot関数でグラフを描画できます。x座標とy座標のデータを渡すだけで、自動的にグラフウィンドウが開きます。labelは凡例、linewidthは線の太さを指定しています。
DataFramesパッケージの使用
using DataFrames
# データフレームの作成(表形式のデータ)
df = DataFrame(
name = ["Alice", "Bob", "Charlie"],
age = [25, 30, 35],
city = ["Tokyo", "Osaka", "Kyoto"]
)
println(df)
# 出力:
# 3×3 DataFrame
# Row │ name age city
# │ String Int64 String
# ─────┼──────────────────────────
# 1 │ Alice 25 Tokyo
# 2 │ Bob 30 Osaka
# 3 │ Charlie 35 Kyoto
DataFrameは、PythonのpandasやRのdata.frameと同様の表形式データ構造です。name、age、cityという列を持ち、3行のデータが格納されています。各列は異なる型を持てます(nameとcityは文字列、ageは整数)。
よく使われるパッケージ一覧
データ処理・可視化
- Plots.jl:グラフ描画、様々な種類のプロット作成
- DataFrames.jl:表形式データの操作
- CSV.jl:CSVファイルの読み書き
- StatsBase.jl:基本的な統計関数
科学技術計算
- DifferentialEquations.jl:微分方程式の数値解法
- Optimization.jl:最適化問題の解法
- LinearAlgebra:線形代数(標準ライブラリ)
機械学習・AI
- Flux.jl:ニューラルネットワーク、深層学習
- MLJ.jl:機械学習フレームワーク
- Turing.jl:ベイズ統計
他言語との連携
- PyCall.jl:PythonライブラリをJuliaから呼び出す
- RCall.jl:RライブラリをJuliaから呼び出す
まとめ:Juliaを選ぶべき理由と今後の展望
Juliaの5つの強み
1. 科学技術計算で圧倒的な速度
C言語並みの性能を持ちながらPythonのように書けます。多くの数値計算でPythonより10〜100倍高速に動作し、大量のデータ処理や複雑な計算で真価を発揮します。
2. 数学的に自然な記法
Unicode対応により、数式をそのままコード化できます。α、β、∑、πなどの数学記号を変数名として使え、論文とプログラムの対応が明確になります。数学者や物理学者にとって直感的です。
3. 開発効率の高さ
コンパイル不要で即座に実行可能。対話的に試しながら開発できるため、試行錯誤が容易です。Pythonのような使いやすさとCのような速度を両立しています。
4. 完全無料のオープンソース
MATLABのような高額なライセンス費用は一切不要。個人でも企業でも教育機関でも、何台のコンピュータにインストールしても追加費用はかかりません。
5. 多言語連携が容易
PyCallでPython、RCallでR、さらにC/Fortranとも連携可能。既存のコードやライブラリを活用しながら、段階的にJuliaへ移行できます。
注意すべき点
初回実行の遅さ(JITコンパイルのコスト)
JITコンパイルのため、関数を初めて実行する際にコンパイル時間がかかります。2回目以降は高速ですが、初回だけは遅いことを理解しておく必要があります。長時間実行するプログラムでは問題になりませんが、短いスクリプトを頻繁に実行する場合は気になるかもしれません。
エコシステムの成長段階
Pythonと比べるとパッケージ数は少なく、一部の分野ではまだ発展途上です。ただし、科学技術計算分野では必要なパッケージは揃っており、PyCallでPythonのライブラリも使えます。
インデックスが1始まり
配列のインデックスが1から始まるため、Pythonユーザーは慣れるまで混乱することがあります。数学的には自然ですが、プログラミングの慣習とは異なります。
こんな人に特におすすめ
**数値計算・科学技術計算を行う研究者**:論文の数式をそのままコードにできる
- データサイエンティスト:大量データの高速処理が可能高速な数値処理が必要な開発者:C言語並みの速度でPythonのように書けるMATLABからの移行を検討している方:構文が似ており移行しやすい、しかも無料Pythonの速度に不満がある方:簡単な移行で大幅な速度向上 最初の一歩を踏み出そうJuliaは科学技術計算の未来を担う言語として、世界中の研究機関や企業で採用が進んでいます。NASAやFDA(米国食品医薬品局)、多くの大学研究室で実際に使われています。完全に無料なので、まずは公式サイトからダウンロードして試してみてください。REPLで簡単な計算から始め、徐々に複雑な処理に挑戦していきましょう。豊富な公式ドキュメントとコミュニティのサポートがあるので、学習環境は整っています。あなたの研究や開発に、Juliaの高速性と使いやすさが新しい可能性をもたらすでしょう。
\ 最新情報をチェック /
